Verifying Infinite Scroll Functionality

Infinite scroll is a popular feature in modern web applications, powering everything from social media feeds to product catalogs. It creates a smooth user experience but also brings unique challenges for QA engineers such as verifying that items load progressively, ensuring API calls trigger correctly, and handling rapid scrolling without glitches. In this post we will explore a demo infinite scroll app and show how to automate its testing with Playwright, covering everything from initial load checks to end of list validation.
The Demo App: Infinite Scroll in Action
Before diving into the tests, let's take a closer look at the demo application we will be working with. The goal of the app is simple: display a list of items that continuously loads as the user scrolls down. While the implementation is lightweight, it includes many of the same behaviors you would find in real production systems.
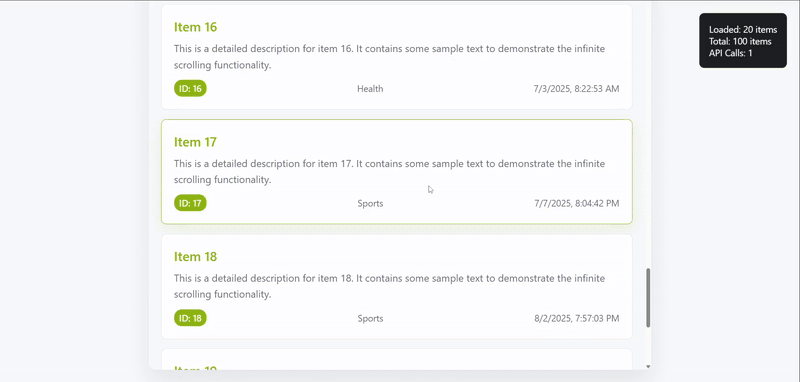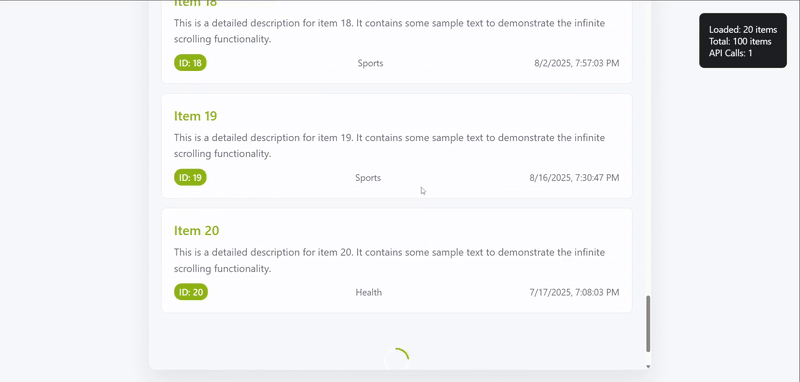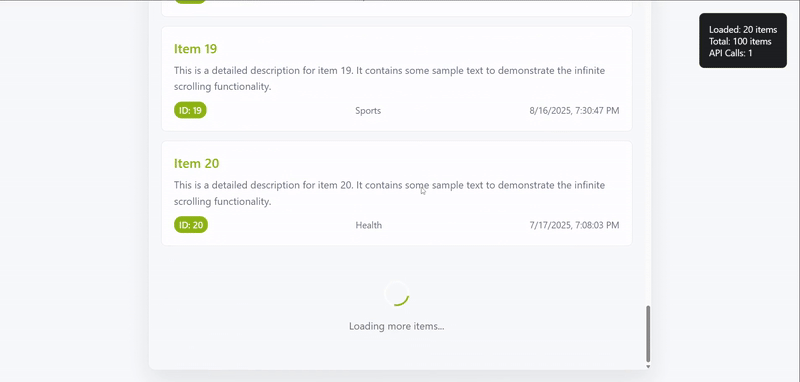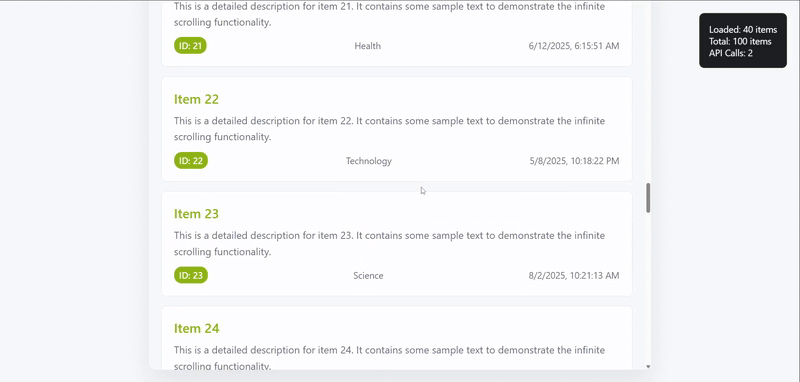
Infinite scroll demonstration
The main parts of the page are:
Beyond the visible elements, the demo app also simulates realistic conditions. Items are fetched in pages with a short delay to mimic network latency, and there is even a small chance of an API failure being triggered. These extra touches make the demo behave much more like a real system and provide plenty of scenarios for automation tests to cover.
Challenges in Testing Infinite Scroll
Testing infinite scroll can be trickier than it looks. Unlike a traditional paginated view where the next set of items is triggered by a clear user action such as clicking a “Next” button, infinite scroll relies on background logic that fires automatically as the user moves through the page. This introduces a number of challenges that QA engineers need to address.
These challenges highlight why infinite scroll requires more than simple assertions about visible elements. The tests need to capture both the dynamic nature of the interface and the correctness of the data flow behind it.
Writing and Walking Through the Test Cases
The Playwright test file is organized to cover every important scenario that an infinite scroll implementation should handle. Each category of tests focuses on a particular aspect of the experience, and together they form a complete safety net for verifying functionality.
The journey begins with the initial load. When the page is first opened, the application should display the first batch of items, and the counters in the stats panel should immediately reflect that at least some items are present. This ensures the application starts in a valid state.
const initialItems = await page.locator('[data-testid^="item-"]').count();
expect(initialItems).toBeGreaterThan(0);
expect(initialItems).toBeLessThanOrEqual(20);
const loadedCount = await page.locator("#loaded-count").textContent();
expect(parseInt(loadedCount)).toBeGreaterThan(0);
const apiCalls = await page.locator("#api-calls").textContent();
expect(parseInt(apiCalls)).toBe(1);
After verifying the starting conditions, the focus shifts to scroll-triggered behavior. As soon as the bottom of the container is reached, the loading section should become visible, complete with the spinner and the loading text.
await page.locator("#listContainer").evaluate(el => {
el.scrollTop = el.scrollHeight;
});
await expect(page.locator("#loading")).toBeVisible();
await expect(page.locator(".loading-spinner")).toBeVisible();
await expect(page.locator("#loading p")).toHaveText("Loading more items...");
The next check confirms that new items are appended to the list when the scroll reaches the bottom. The number of items must increase and the count of API calls should rise by one.
const initialCount = await page.locator('[data-testid^="item-"]').count();
const initialApiCalls = parseInt(await page.locator("#api-calls").textContent());
await page.locator("#listContainer").evaluate(el => {
el.scrollTop = el.scrollHeight;
});
await page.waitForFunction(expected =>
document.querySelectorAll('[data-testid^="item-"]').length > expected,
initialCount
);
const newCount = await page.locator('[data-testid^="item-"]').count();
expect(newCount).toBeGreaterThan(initialCount);
const newApiCalls = parseInt(await page.locator("#api-calls").textContent());
expect(newApiCalls).toBe(initialApiCalls + 1);
Progressive loading ensures that multiple scrolls add new batches one after the other. This simulates a user browsing through longer feeds and helps validate that the list continues to expand without interruption.
for (let i = 0; i < 3; i++) {
await page.locator("#listContainer").evaluate(el => {
el.scrollTop = el.scrollHeight;
});
await page.waitForFunction(count =>
document.querySelectorAll('[data-testid^="item-"]').length > count,
await page.locator('[data-testid^="item-"]').count()
);
}
Edge conditions are equally important. When all one hundred items are loaded, the end message must appear and the app should stop making new requests. Conversely, if the user scrolls only halfway down, nothing should happen until the bottom is reached.
await expect(page.locator("#endMessage")).toBeVisible();
await page.locator("#listContainer").evaluate(el => {
el.scrollTop = el.scrollHeight * 0.5;
});
await page.waitForTimeout(2000);
await expect(page.locator("#loading")).not.toBeVisible();
Another layer of validation involves checking that items are loaded in the correct order and contain the right content. This ensures that the sequence is consistent and no duplicate entries are introduced.
const items = await page.locator('[data-testid^="item-"]').all();
const itemTitle = await items[0].locator("h3").textContent();
expect(itemTitle).toBe("Item 1");
const itemId = await items[0].getAttribute("data-item-id");
expect(parseInt(itemId)).toBe(1);
Finally, the stats panel acts as a reliable source of truth. The loaded item count shown to the user must always match the number of elements in the DOM, and the API call counter should be accurate.
const loadedCount = parseInt(await page.locator("#loaded-count").textContent());
const actualCount = await page.locator('[data-testid^="item-"]').count();
expect(loadedCount).toBe(actualCount);
By walking through each of these cases, the test suite achieves both breadth and depth. It covers the smooth flow of a user scrolling gradually through content, the fast interactions of a user flicking to the bottom, and the edge conditions that define when the system should stop. Together, these tests provide confidence that the infinite scroll behaves reliably under different scenarios.
Best Practices for Infinite Scroll Testing
Automating infinite scroll comes with a unique set of challenges, and following a few best practices makes the process much more reliable. One of the most important techniques is using waitForFunction to check for changes in the DOM instead of relying on fixed waits. Since content loads asynchronously, waiting for a condition such as “the number of items is greater than before” ensures the test only proceeds once the page is actually ready.
Timeouts are another factor that should be handled carefully. Adding them generously provides enough time for slower responses or network delays, but they should not be excessive. A smart balance allows the tests to stay stable without making them unnecessarily long.
When simulating user actions, it is valuable to test both gradual scrolling and rapid scrolling. Real users interact with applications in different ways, and infinite scroll should handle both patterns gracefully. Tests that mimic fast flicking to the bottom of the list can catch issues such as multiple duplicate requests, while slower scrolling validates that batches load progressively.
Validation should not stop at the visible interface. The frontend state, like a spinner appearing and disappearing, is important, but so is the backend effect. Checking the API call counter ensures that the system is making the right number of requests at the right time, giving confidence that the data pipeline is functioning correctly.
Finally, keeping test data deterministic wherever possible makes debugging much easier. In the demo application, the total number of items is fixed, and the structure of each batch is predictable. This helps create stable tests that consistently verify expected outcomes. In real applications, controlling data fixtures and using mock responses can provide the same benefit.
Together, these practices help make infinite scroll tests both robust and maintainable, turning what could be a flaky area of automation into a reliable part of the test suite.
Conclusion
Infinite scroll is a powerful feature that can greatly improve the user experience, but it also introduces complexities that demand thoughtful testing. By breaking the problem into clear scenarios—initial load, progressive loading, edge conditions, and rapid interactions—it becomes possible to design tests that reflect how real users interact with the application. Playwright's ability to handle dynamic content, combined with good practices like condition-based waits and realistic simulations, makes it a strong choice for this type of automation.
The demo application and its test suite demonstrate how these ideas can be applied in practice, showing not only how to validate the user interface but also how to confirm the accuracy of backend interactions. With this foundation, we can confidently extend the same approach to more complex production systems such as e-commerce product listings, news feeds, or dashboards.
For those who want to explore further, the complete code examples along with the demo application are available on our GitHub page. See you in the next one!