The Power of Mutation Testing

In the intricate world of software development, where every line of code is a potential breeding ground for bugs, the quest for flawless software remains a perpetual challenge. Software bugs, like hidden gremlins, have the uncanny ability to disrupt applications, erode user trust, and tarnish the reputation of even the most meticulously crafted programs. As developers grapple with the complexities of writing robust code, the need for innovative quality assurance methodologies becomes increasingly apparent.
Enter mutation testing - an unsung hero in the realm of software quality assurance. It's not just about fixing bugs; it's about fortifying code against the unforeseen. In the ever-evolving landscape of software development, where new features and updates are introduced regularly, ensuring the reliability of existing code is non-negotiable. This blog post embarks on an exploration of mutation testing, unveiling its core concepts, dissecting its various mutations, and shedding light on its pivotal role in enhancing the overall quality of software.
Core Concepts of Mutation Testing
Mutation testing operates as a vigilant guardian in the world of software development, tirelessly assessing the resilience of our code. At its essence, mutation testing introduces deliberate and controlled modifications, known as mutants, into the existing codebase. These mutants represent potential errors or bugs that might be lurking within the program. The primary goal is to scrutinize the effectiveness of our test suites by observing how well they can detect and neutralize these injected mutants.
Imagine each mutant as a simulated flaw - ranging from simple syntactical changes to more complex alterations in logic or semantics. The success of our test suite is measured by its ability to recognize and flag these mutations. In essence, mutation testing seeks to answer a critical question: How robust is our testing strategy in the face of subtle code variations?
Process Overview
Mutation testing unfolds in a series of meticulous steps, each contributing to a comprehensive evaluation of our test suites.
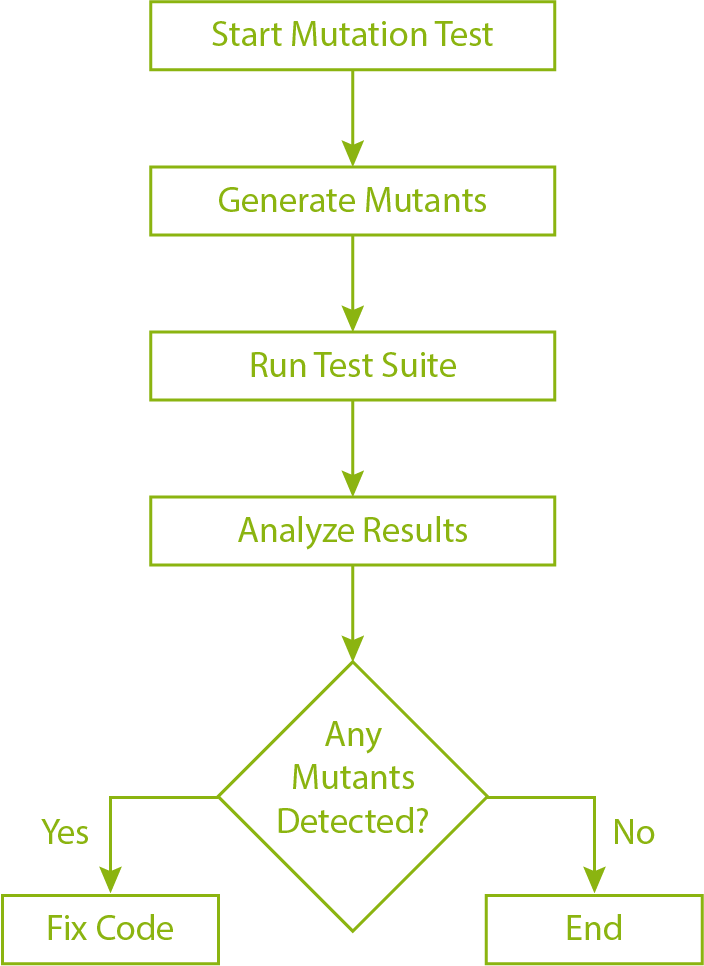
Mutation testing acts as a stringent examiner, challenging the test suite's capability to catch subtle anomalies. By scrutinizing the program's response to these deliberately induced changes, developers gain a clearer understanding of the overall effectiveness of their testing strategies. This not only ensures the identification of existing bugs but also aids in fortifying the code against future vulnerabilities.
Types of Mutations
Mutation testing introduces a spectrum of intentional alterations to the code, each designed to scrutinize different facets of our test suite's effectiveness. These mutations can be broadly categorized into syntax mutations, logical mutations, and semantic mutations.
Syntax Mutations
In the realm of syntax mutations, the focus is on deliberately tweaking the structure of the code without changing its underlying logic. This could involve modifying operators, changing variable names, or altering the arrangement of statements. By perturbing the syntactical elements, mutation testing evaluates how well our test suite can identify and rectify superficial errors in the code. Syntax mutations simulate common mistakes that developers might make, such as typos or syntax errors, and challenge the test suite to catch these seemingly minor discrepancies.
Original Code:
def add_numbers(a, b):
return a + b
Mutated Code (Syntax Change):
def add_numbers(a, b):
return a * b
In this syntax mutation, the addition operator is changed to the multiplication operator, introducing a syntactical error.
Logical Mutations
Moving beyond the surface-level modifications, logical mutations delve into the heart of the program's decision-making processes. These alterations involve changing the logical conditions, control structures, or loop constructs within the code. The objective is to assess the test suite's ability to detect more nuanced errors that might impact the program's behavior. Logical mutations simulate scenarios where the code logic is subtly altered, challenging the test suite to recognize and respond to changes that go beyond mere syntax.
Original Code:
def is_positive(number):
return number > 0
Mutated Code (Logical Change):
def is_positive(number):
return number < 0
Here, the logical condition is mutated, changing the original check for positivity to a check for negativity.
Semantic Mutations
Semantic mutations take the scrutiny a step further by tampering with the meaning of the code. This category involves introducing modifications that alter the fundamental logic and functionality of the program. Semantic mutations challenge the test suite to detect changes in program behavior resulting from modifications to algorithms, data structures, or the overall logic flow. By exploring how well the test suite adapts to these deeper alterations, semantic mutations offer insights into the robustness of our testing strategy against more profound code changes.
Original Code:
def calculate_area(radius):
return 3.14 * radius * radius
Mutated Code (Semantic Change):
def calculate_area(radius):
return 2 * 3.14 * radius
Semantic mutations alter the meaning of the code. In this case, the formula for calculating the area of a circle is changed, introducing a semantic error.
In essence, the combination of syntax, logical, and semantic mutations provides a comprehensive evaluation of the test suite's resilience against a spectrum of potential errors. The varying levels of complexity in these mutations mirror the diverse challenges that developers face in ensuring the stability and reliability of their software.
Benefits of Mutation Testing
Mutation testing isn't just a rigorous examination; it's a strategic investment in the quality assurance process. The benefits extend beyond mere bug detection, touching upon the very foundations of software reliability and efficiency.
Improved Test Suite Effectiveness
Mutation testing serves as a litmus test for the effectiveness of our test suite. By intentionally introducing mutants - simulated defects - into the codebase, it becomes a powerful mechanism for identifying areas where the existing test suite may fall short. The process ensures that not only obvious bugs but also subtle, elusive defects are captured, allowing developers to fortify their test suites comprehensively. Improved test suite effectiveness means a higher likelihood of catching real defects in the code, leading to a more robust and resilient software product.
Increased Confidence in Code Quality
The meticulous scrutiny offered by mutation testing instills a profound sense of confidence in the overall quality of our codebase. Successfully identifying and addressing mutants demonstrates that our test suite is adept at distinguishing between correct and faulty code variations. This heightened confidence isn't just about bug detection; it's about knowing that our code can withstand the unforeseen challenges that may arise during its lifecycle. For developers and stakeholders alike, this confidence is invaluable, fostering trust in the reliability of the software being delivered.
Cost Savings in the Long Run
Early detection of potential issues is a cornerstone of efficient software development, and mutation testing excels in this regard. By uncovering vulnerabilities during the testing phase, developers can address issues before they escalate into more complex and costly problems in later stages of the development lifecycle. The proactive nature of mutation testing contributes to significant cost savings by preventing the propagation of defects through subsequent phases. As the saying goes, an ounce of prevention is worth a pound of cure, and mutation testing provides that essential ounce by identifying and rectifying issues before they become costly challenges down the road.
As we can see, the benefits of mutation testing extend far beyond the immediate realm of bug detection. They encompass a strategic approach to quality assurance, instilling confidence, and ensuring the long-term cost-effectiveness of software development endeavors.
Advanced Mutation Testing Techniques
While the fundamental principles of mutation testing lay a robust foundation, advanced techniques bring a new level of sophistication to the process. Two noteworthy methodologies that elevate mutation testing are higher-order mutations and fuzzing.
Higher-Order Mutations
As the sophistication of software applications continues to grow, so does the need for more intricate testing methodologies. Higher-order mutations step into this arena by introducing mutations of increased complexity. Unlike traditional mutations that focus on individual lines or statements, higher-order mutations manipulate multiple elements simultaneously, challenging the test suite to discern and address intricate variations in the code. This technique goes beyond the surface, testing the depth and adaptability of the test suite against more nuanced changes in the program's logic. By elevating the complexity of mutations, higher-order mutations provide a more comprehensive evaluation of the test suite's resilience, ensuring that it can withstand the intricacies of modern software development.
Fuzzing
While mutation testing introduces deliberate changes to the code, fuzzing takes a slightly different approach by bombarding the program with a barrage of unexpected and random inputs. The combination of fuzz testing and mutation testing creates a formidable duo, expanding the scope of test coverage. Fuzzing aims to identify vulnerabilities that might not be uncovered through traditional testing methods. When integrated with mutation testing, it further broadens the spectrum of potential defects that can be discovered. This dynamic duo works synergistically - mutation testing provides a controlled environment for deliberate changes, while fuzzing injects randomness to simulate real-world scenarios. Together, they offer a powerful strategy for uncovering hidden bugs and enhancing the overall robustness of the software.
In essence, these advanced mutation testing techniques go beyond the conventional, pushing the boundaries of what can be assessed and ensuring that software is tested not just for the expected but also for the unexpected. As the complexity of software systems increases, these techniques become indispensable in the quest for comprehensive quality assurance.
Mutation Testing for Code Coverage Analysis
As a crucial component of the software testing arsenal, mutation testing plays a distinctive role in tandem with traditional code coverage analysis. Understanding this synergy is essential for ensuring a holistic evaluation of the testing landscape.
Role in Code Coverage
Code coverage analysis provides insights into the extent to which our codebase is exercised by our test suite. However, it doesn't necessarily guarantee the detection of real defects. This is where mutation testing steps in as a complementary force. While code coverage indicates which lines of code are executed during testing, mutation testing assesses the test suite's ability to catch errors within those executed lines. In essence, mutation testing adds a qualitative layer to the quantitative data provided by code coverage analysis. It's not just about the quantity of covered code; it's about the quality of testing within that coverage, ensuring that the tests are robust and effective in identifying potential defects.
Identifying Gaps
One of the distinctive strengths of mutation testing lies in its ability to pinpoint gaps in test coverage that traditional metrics might overlook. By introducing deliberate mutations into the codebase, mutation testing acts as a detective, uncovering areas that are not adequately scrutinized by existing test cases. If a mutation goes undetected, it indicates a gap in the test suite, revealing a potential blind spot where real defects could lurk. This process of uncovering untested paths ensures a more thorough examination of the code, leading to a more resilient software product. The insights gained from mutation testing not only enhance the overall testing strategy but also guide developers in refining and expanding their test suites to cover previously overlooked areas.
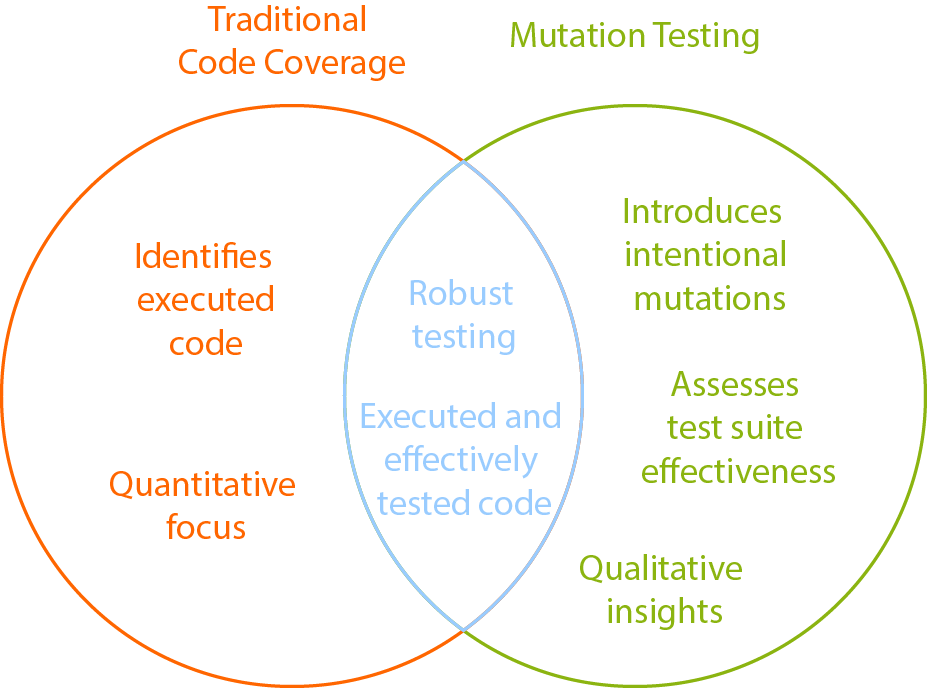
In summary, mutation testing and code coverage analysis form a symbiotic relationship. While code coverage provides a quantitative measure of testing reach, mutation testing brings a qualitative dimension, ensuring that the covered code is effectively tested for potential defects. Together, they offer a comprehensive approach to evaluating the testing landscape and fortifying software against unforeseen vulnerabilities.
Mutation Testing for Test Case Generation
Mutation testing not only serves as a vigilant watchdog for existing test suites but also plays a pivotal role in the proactive generation and enhancement of test cases. This dual functionality transforms mutation testing into a powerful tool for test case improvement and integration into automated testing processes.
Test Case Improvement
The insights gained from mutation testing go beyond identifying existing weaknesses in test suites; they also provide valuable guidance for crafting more effective test cases. When a mutant is detected, it signifies a scenario where the existing test suite failed to catch a simulated defect. This information serves as a roadmap for test case improvement, guiding developers to create additional test cases that specifically target the identified weaknesses. By systematically addressing the types of mutations that went undetected, the test suite becomes more robust and comprehensive. Mutation testing results, therefore, become a catalyst for continuous improvement, driving the evolution of test cases to match the ever-changing landscape of software development.
Automation Integration
As the software development landscape embraces automation for efficiency and speed, integrating mutation testing into automated testing processes becomes a strategic move. Automation streamlines the mutation testing workflow, allowing for frequent and consistent testing throughout the development lifecycle. Continuous integration pipelines can be configured to incorporate mutation testing, ensuring that every code change is subjected to the rigorous scrutiny of mutants. Automated mutation testing not only accelerates the testing process but also facilitates quick feedback to developers, enabling them to address potential issues promptly. The integration of mutation testing into automated workflows enhances the overall efficiency of the testing pipeline, fostering a culture of proactive quality assurance.
Mutation testing becomes a dynamic force not just for identifying weaknesses but for actively shaping the trajectory of test case development. The integration of mutation testing into automated processes further cements its role as a proactive and efficient guardian in the realm of software quality assurance.
Conclusion
In unraveling the intricacies of mutation testing, we've explored its fundamental concepts, delved into the various types of mutations, and uncovered the manifold benefits it brings to the table. From improving test suite effectiveness to integrating advanced techniques like higher-order mutations and fuzzing, mutation testing stands as a formidable ally in the pursuit of software quality. Its role in code coverage analysis reveals the synergy between quantitative and qualitative testing metrics, while its influence on test case generation emphasizes its proactive nature in refining and expanding test suites.
As we navigate the ever-evolving landscape of software development, the importance of mutation testing in maintaining high-quality software cannot be overstated. Beyond its role as a bug-detection mechanism, mutation testing serves as a compass, guiding developers towards a deeper understanding of their code's resilience and vulnerabilities. It instills confidence in the reliability of software, fostering a culture of proactive quality assurance that is essential in the face of increasing software complexity and rapid development cycles.
Now, as we conclude this exploration into the realm of mutation testing, the journey continues for each reader. I invite you to embark on your own exploration of mutation testing in your QA processes. Implement it in your projects, witness its impact, and share your experiences with the community. By collectively embracing and refining mutation testing practices, we contribute not only to the fortification of our individual projects but also to the advancement of quality assurance practices across the software development ecosystem.